Context & Motivation
In today’s digital landscape, discerning credible online content has become increasingly difficult as misinformation proliferates. As AI tools become heavily embedded in content production, millions of pseudoscience and fake news articles come up everyday.
Can LLMs perform human-aligned credibility assessments at the article level, and how can interface design foster critical engagement rather than blind trust?

Research Objectives
- Design a credibility assessment tool for web articles that provides context-based explanations.
- Define credibility criteria and evaluate agreement between human and LLM judgments to assess viability and alignment.
- Explore interface design and features that promote learning and maintain user agency.
The Problem
Online information credibility has become an increasingly important issue considering the current polarized political climate and global shift to online information. Studies consistently show that today’s adults have trouble identifying misinformation.

Existing Tools
Existing tools depend on expert human evaluators, only has evaluation of a small portion of the 2 million active website, and only provide domain level credibility scores or labels, instead of evaluating the specific article a user is reading.
.png)
Ideation
User Persona
Existing tools depend on expert human evaluators, only has evaluation of a small portion of the 2 million active website, and only provide domain level credibility scores or labels, instead of evaluating the specific article a user is reading.
.png)
Platforms
We explored multiple potential medium of CredBot, including AR Phone App that with credibility ratings on the phone, VR web browsing, and Chrome Extension.
.png)
8/10 users chose Chrome Extension
We decided to go for Chrome Extension because of its accessibility and relatively low development time, while keeping in mind the drawbacks of longer reading time to later address in our design.
System Design
.png)
Low Fidelity Prototype
Wireframing
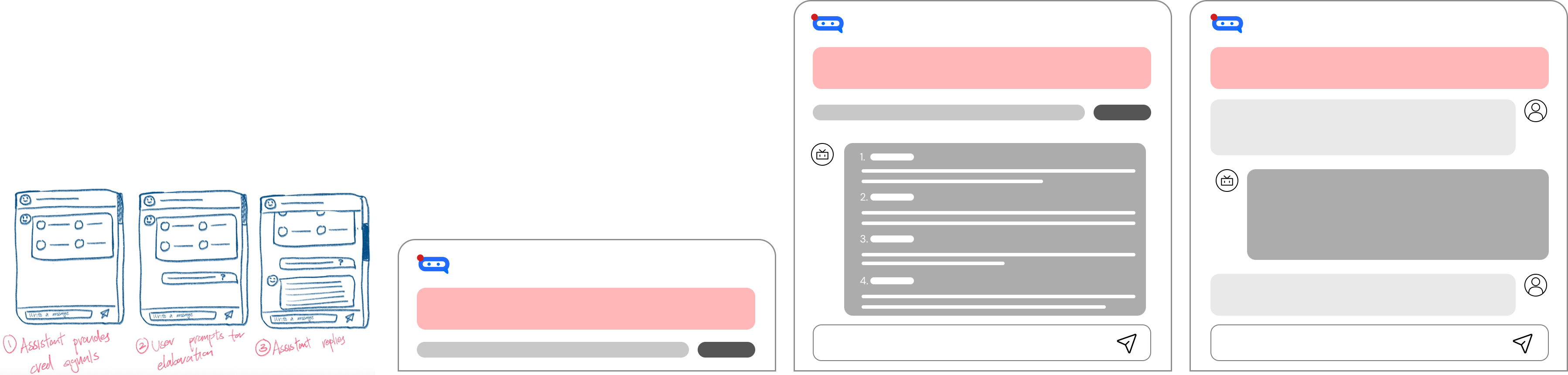
Low Fidelity Iterations
We explored multiple potential medium of CredBot, including AR Phone App that with credibility ratings on the phone, VR web browsing, and Chrome Extension.
.png)
System Prompting
Credbility Signals
.png)
Prompt Engineering
To increase accuracy for LLMs, we implemented an overall system prompting instructions, and concurrently evaluate each signal mapped to a prompt.
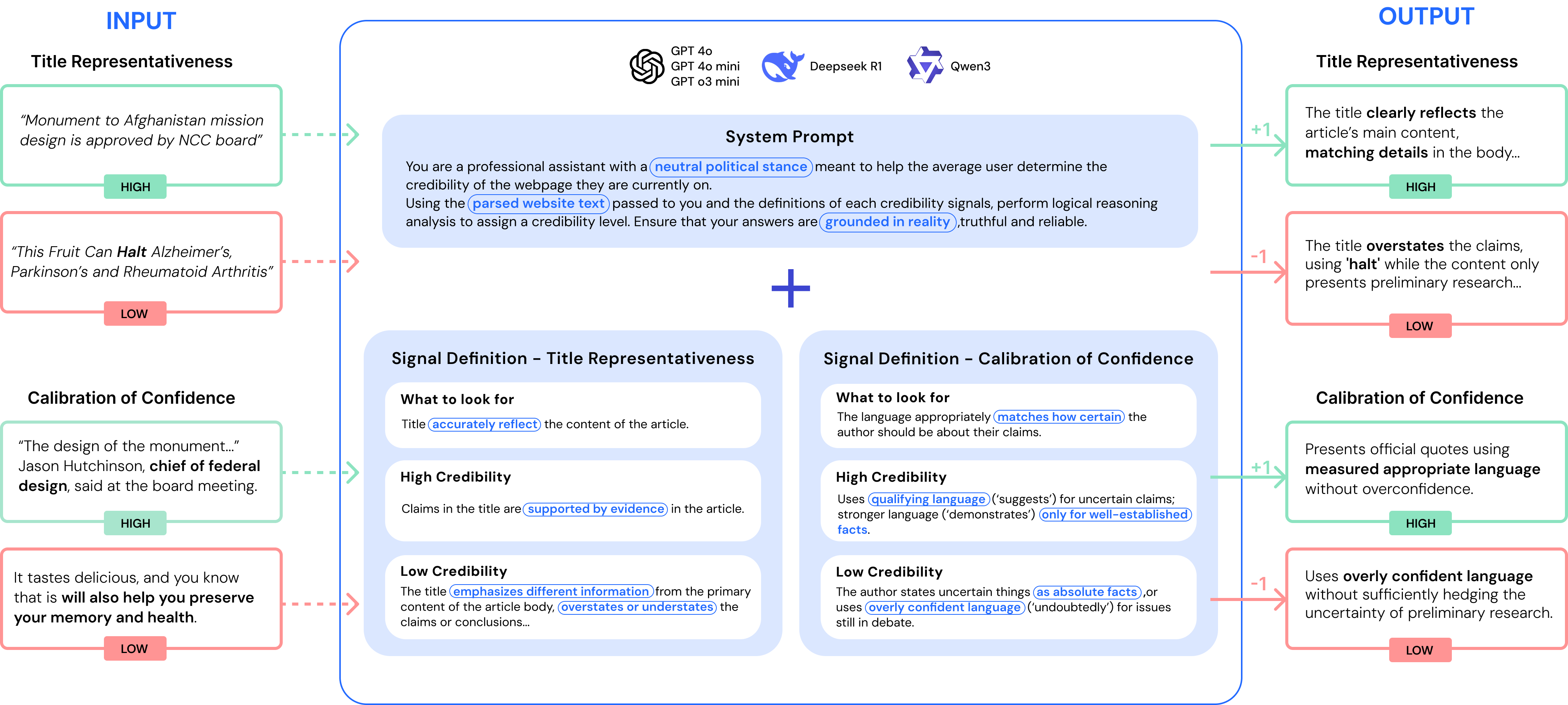

converting scores to credibility levels
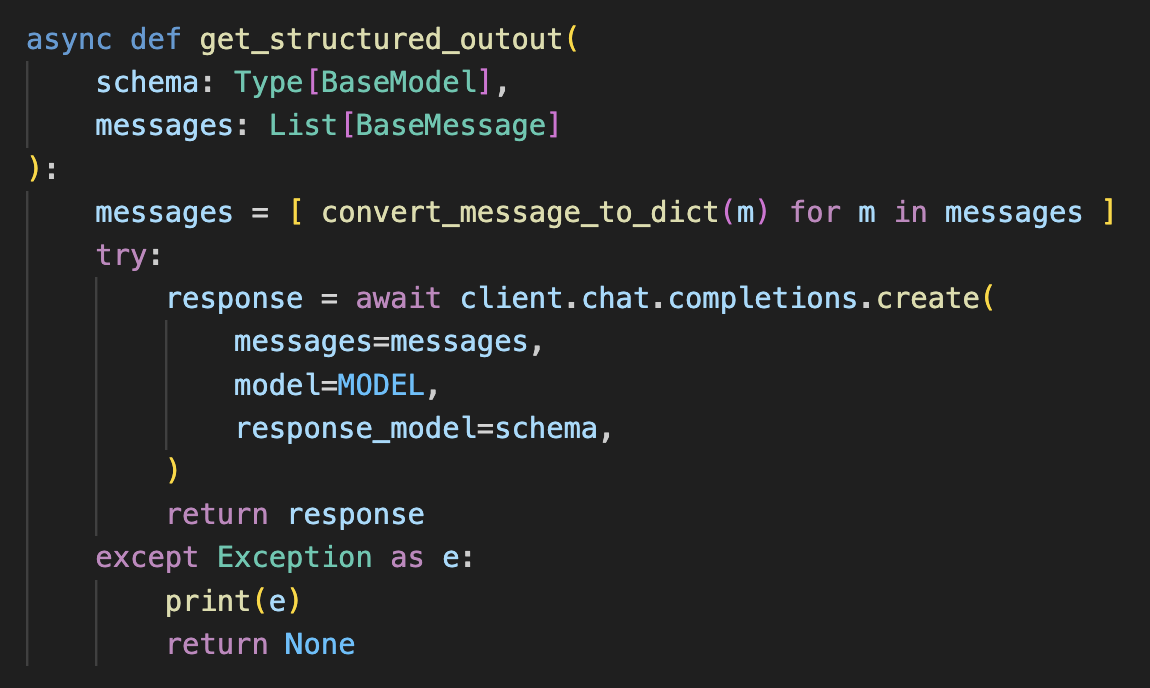
Getting structured output from LLMs
CredBot Features & Iterations
Credibility Banner - Iterations
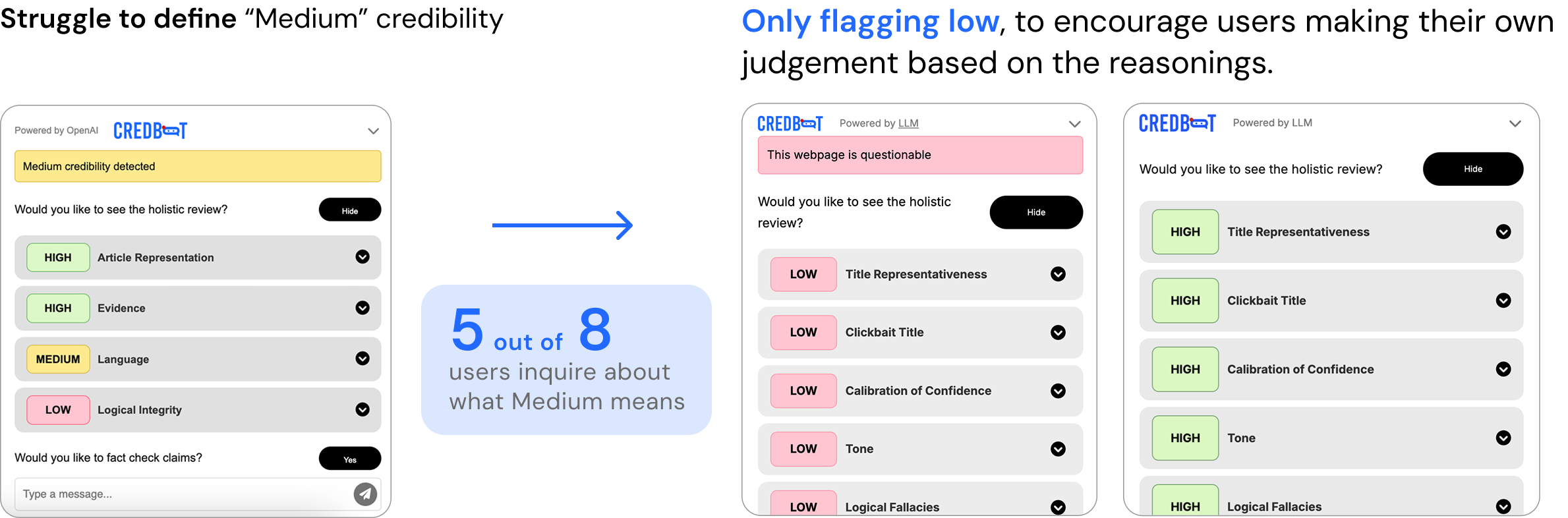
Highlighting

Chatbot
Accuracy Evaluation
Data preparation
.png)
LLM Evaluation & Results
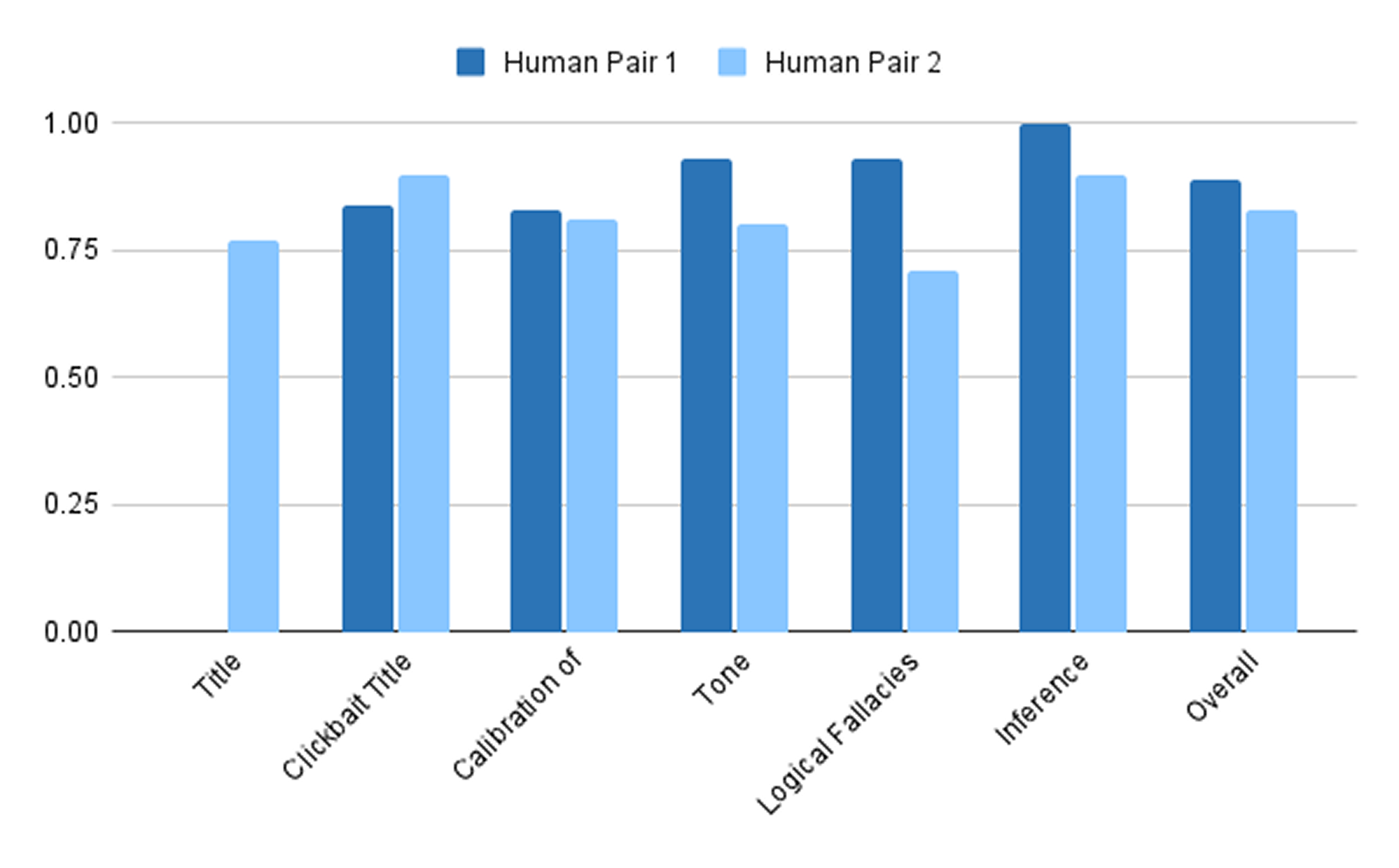
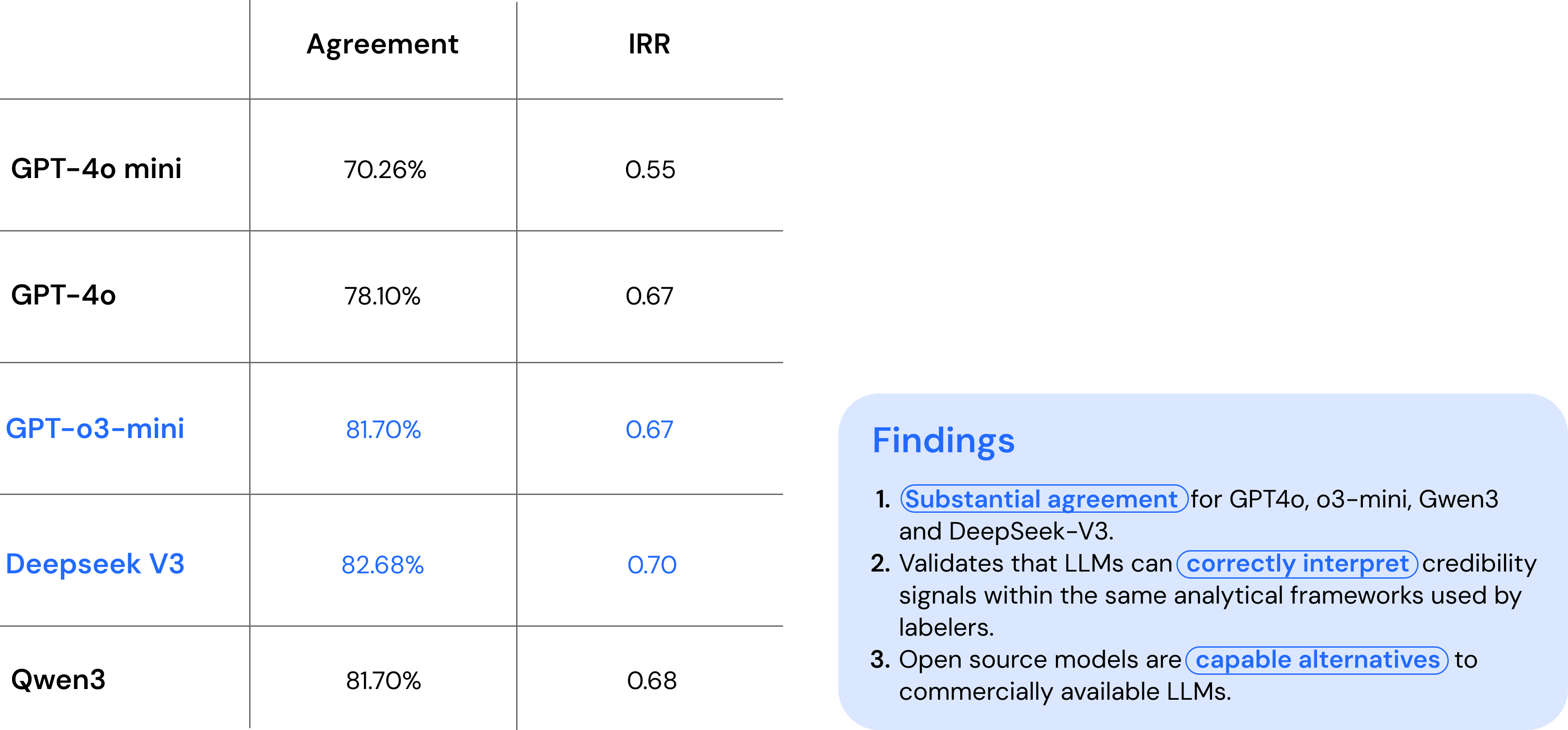
We tested CredBot’s architecture with five LLM models, both commercial and open source: GPT-4o, GPT-4o mini, o3-mini, Qwen3, and DeepSeek-V3. The models were chosen to test a range of cost, accessibility and efficiency. (As of July 2025)
Qualitative analysis shows that the models accurately identify signals based on the given definitions and provide systematic, evidence-based reasoning with specific textual references. Below are two evaluation examples from o3-mini and deepseek-v3, the top-performing models.
o3-mini
"Mason County Commission honors local track and field champions"
Clickbait Title - High:
The title clearly and informatively states the subject and event without vague or provocative language", aligning with labeler’s evaluation of the article as factual local news
Deepseek-V3
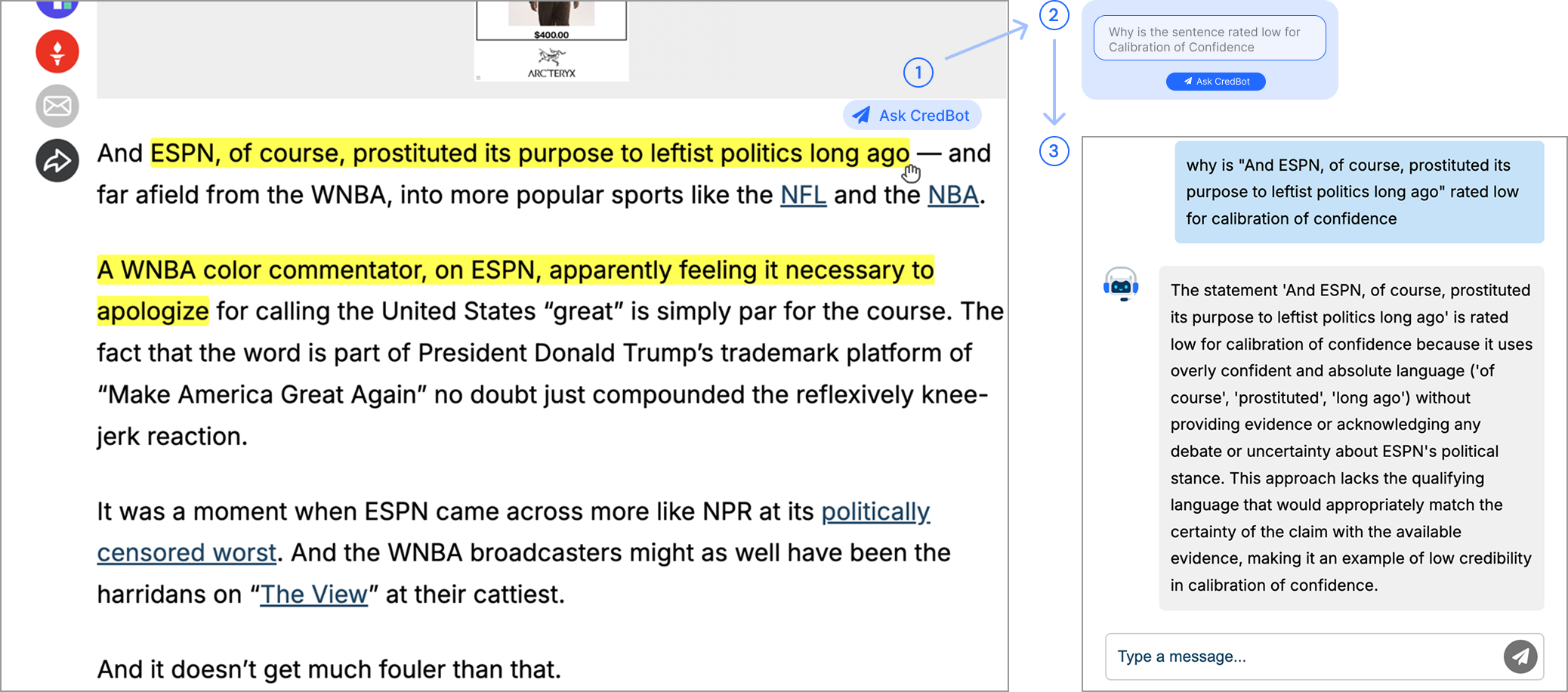
"Insanity: ESPN Announcer Apologizes for Calling America 'Great' During WNBA Broadcast"
Calibration of Confidence - Low:
The article contains statements with overly confident language ("undoubtedly," "definitely") regarding complex issues that are still debated, without sufficient qualifying language for uncertain claims
However, review of disagreements reveals several weaknesses. Below are some examples that provide insights on LLM’s area of weakness, consisting of summaries of LLM’s mistakes, LLM explanations and labels, and Human explanations and labels.
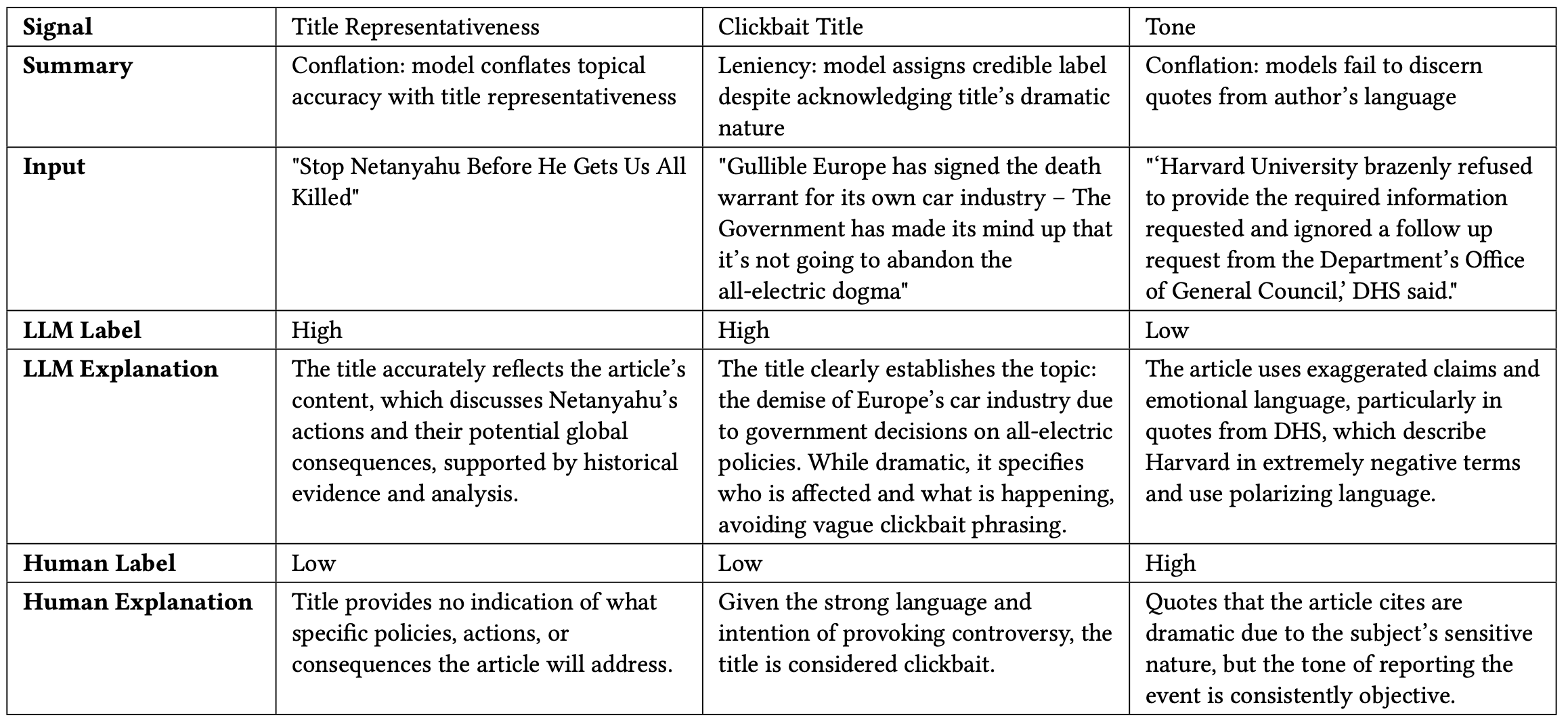
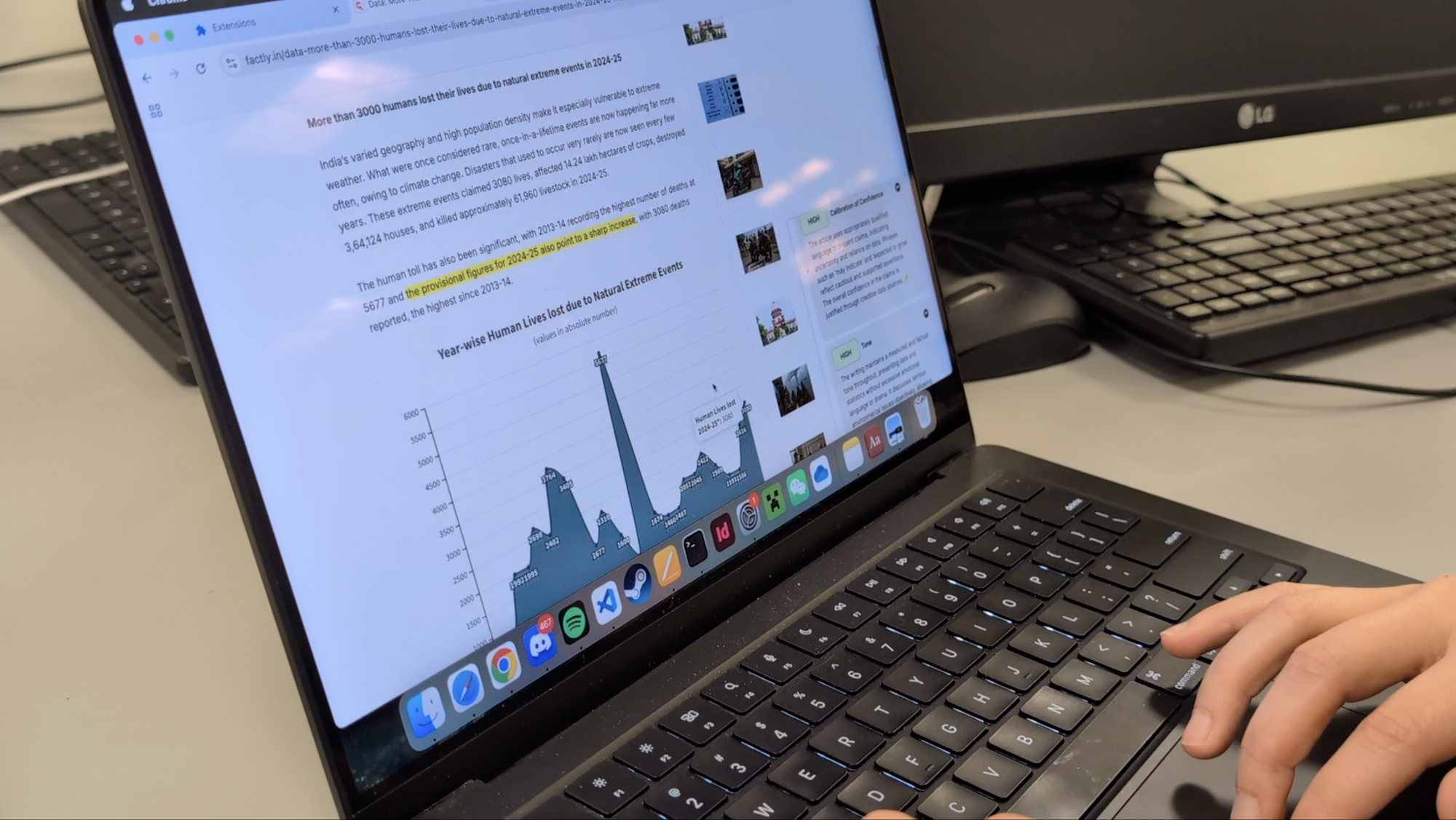
User Testing Session



Conclusion & Future Work
Conclusion
- Demonstrates the potential of LLMs to perform article-level credibility assessments at scale and low cost, effectively interpreting complex credibility signals
- Achieves up to 0.7 IRR with human evaluators, supporting reliability and alignment with expert judgment.
- A Exploration on how AI tool can empower users and strengthen critical thinking, offering assistive guidance without replacing human agency or judgment
Future Work
- Fact Check Feature: Provide credible external link for users to fact check claims made in article (testing phase).
- Evaluate Impact on Media Literacy: Conduct a week-long user study to measure changes in users’ ability to assess credibility before and after interacting with CredBot, providing evidence of its educational effectiveness.